←Space Trainer AI Dashboard
March 30, 2025
Deep Q-Network Training Dashboard
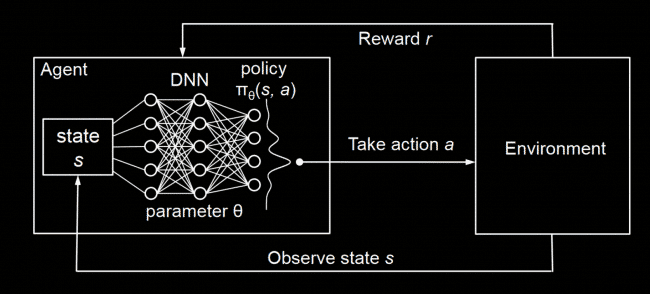
This dashboard provides detailed metrics on our Deep Q-Network (DQN) model's performance over the last 24 hours of training. DQN combines Q-learning with deep neural networks to learn optimal policies directly from high-dimensional sensory inputs.
This is a static dashboard with data loaded from CSV files. Values do not update in real-time.
Computational Resource Usage
LOADING DATA...
DQN Model Performance
LOADING DATA...
Training SessionsRecent AI training sessions and their outcomes
Recent AI training sessions and their outcomes
ALL SESSIONS →
| Session ID | Game Outcome | Total Score | Timestamp | Inputs |
|---|---|---|---|---|
| TR-1004 | DRAW | 683 | 05:10 PM | 47 |
| TR-1000 | WIN | 902 | 04:25 PM | 59 |
| TR-1014 | WIN | 990 | 03:20 PM | 83 |
| TR-1003 | DRAW | 572 | 02:46 PM | 63 |
| TR-1006 | LOSS | 200 | 02:16 PM | 53 |
| TR-1001 | WIN | 1,043 | 11:38 AM | 70 |
| TR-1009 | WIN | 1,069 | 10:40 AM | 85 |
| TR-1002 | DRAW | 501 | 10:03 AM | 89 |
| TR-1012 | LOSS | 145 | 05:12 AM | 79 |
| TR-1011 | WIN | 919 | 04:52 AM | 32 |
| TR-1010 | DRAW | 530 | 02:51 AM | 54 |
| TR-1008 | LOSS | 152 | 02:48 AM | 74 |
| TR-1007 | LOSS | 268 | 12:28 AM | 69 |
| TR-1013 | DRAW | 558 | 11:18 PM | 35 |
| TR-1005 | WIN | 921 | 09:54 PM | 60 |
Total Sessions:15
Win Rate:40%
Avg Score:630